


编译 | 陈骏达编辑 | Panken
智东西6月7日消息,6月4日,曾因“泄密”被OpenAI开除的OpenAI前超级对齐部门成员利奥波德·阿申布伦纳(Leopold Aschenbrenner)在Dwarkesh播客上公开发声,称自己是因为向董事会分享安全备忘录才被OpenAI开除的。
OpenAI超级对齐团队的工作经历,让阿申布伦纳能在AI发展的最前沿见证此项技术的种种机遇和风险,他也于6月4日在自己的网站上公布了一份长达165页的PDF文档,给出了对AI趋势的推测。他还澄清道,虽然自己曾在OpenAI工作,但自己的预测都是基于公开信息、自己的想法、一般性的田野知识和工作期间的八卦。

阿申布伦纳在这份文件的开头特别致敬了前OpenAI首席科学家伊尔亚·苏茨克维(Ilya Sutskever)和其它OpenAI超级对齐团队的成员。在伊尔亚从OpenAI淡出直到离职的几个月中,众多网友都发出疑问:伊尔亚究竟看到了什么?或许这份文件能让我们从顶尖AI研究者的视角,一窥未来AI的发展趋势。
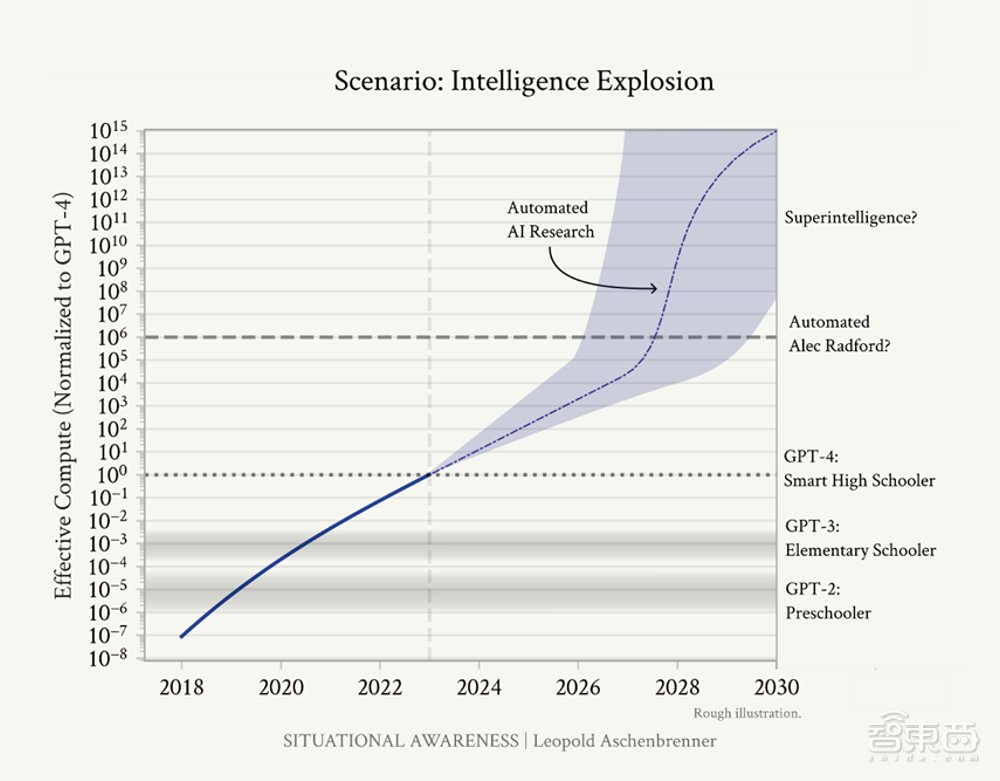
阿申布伦纳认为,AGI(通用人工智能)的竞赛已经悄然开始,我们有很大概率将在2027年实现AGI系统。并且,AI系统并不会在达到人类水平后就止步不前,而是会在数以亿计的AGI带领下实现自动化的AI研究,或许能在1年时间内做出原本10年才能实现的算法进步,我们或许会在2030年左右迎来真正意义上的超级智能。
然而AI系统的快速进步也将给人类带来诸多挑战。阿申布伦纳认为控制超人类水平的AI系统仍然是一个尚未解决的技术问题。虽然这一技术是可以实现的,但在“智能爆炸”的背景下,相关研究很可能会脱离正轨,这极有可能带来灾难性的后果。
阿申布伦纳将他的这份文件命名为《态势感知》(Situational Awareness),他认为目前全世界只有仅仅几百人对AI的发展有真正意义上的感知,并且大多集中在旧金山地区以及全球各地的AI实验室里,而自己便是这几百人中的一员。主流专家们目前还停留在AI仅仅是“下一词预测”的认知上,但AI或许会成为一场远超互联网的宏大的技术变革。
在这份PDF文档中,阿申布伦纳先是对GPT-4到AGI的发展路径做出了预测。他认为,算力和算法效率都在以每年0.5个数量级(1个数量级=10倍)的速度发展,再加上可能出现的释放模型性能的技术突破,我们极有可能于2027年实现AGI。这意味着模型将能完成AI研究员或者工程师的工作。
阿申布伦纳对AI水平发展的估计参考了GPT-2到GPT-4的发展趋势。2019年的GPT-2模型可以简单地串起一些看似合理的句子,但是却无法从1数到5,也无法完成总结类任务。GPT-2模型的水平大概与学龄前儿童相仿。
而2020年的GPT-3模型能生成篇幅更长的模型,并能完成一些基础的算术任务和语法纠错。GPT-3模型大致达到了小学生的水平。2年之后发布的GPT-4模型能编写复杂的代码并进行迭代调试,还能完成高中数学竞赛题,击败了大多数高中生,实现了与较为聪明的高中生相似的水平。
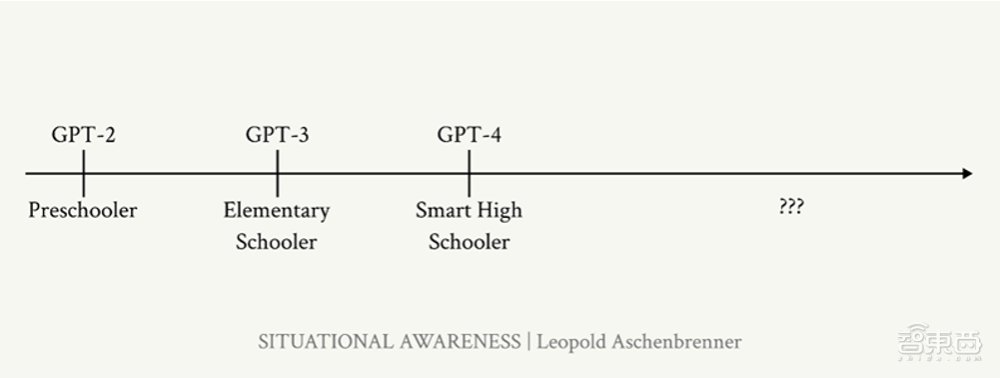
不过,阿申布伦纳也提到,将AI的能力与人类智能进行比较是困难且有缺陷的,但这样的类比仍然是有借鉴意义的。
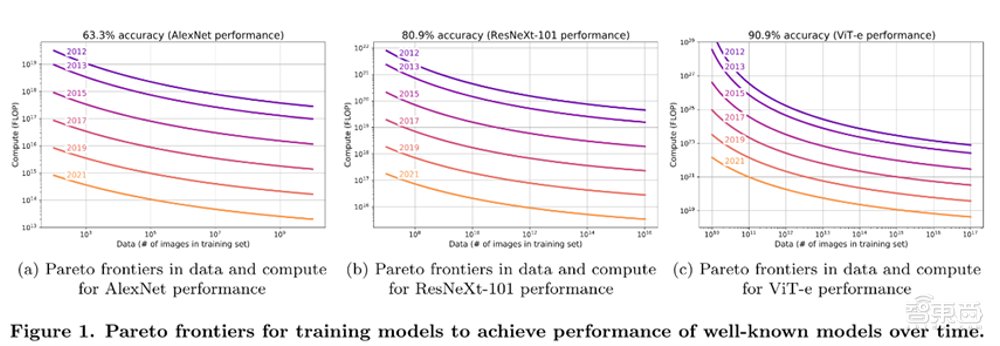
过去10年深度学习的进步速度非常惊人。仅仅10年前,深度学习系统识别简单图像的能力就已经是革命性的。但如今,我们不断尝试提出新颖的、更难的测试,但每个新的基准测试都很快被破解。
过去,破解广泛使用的基准测试需要数十年的时间,而现在只要几个月。
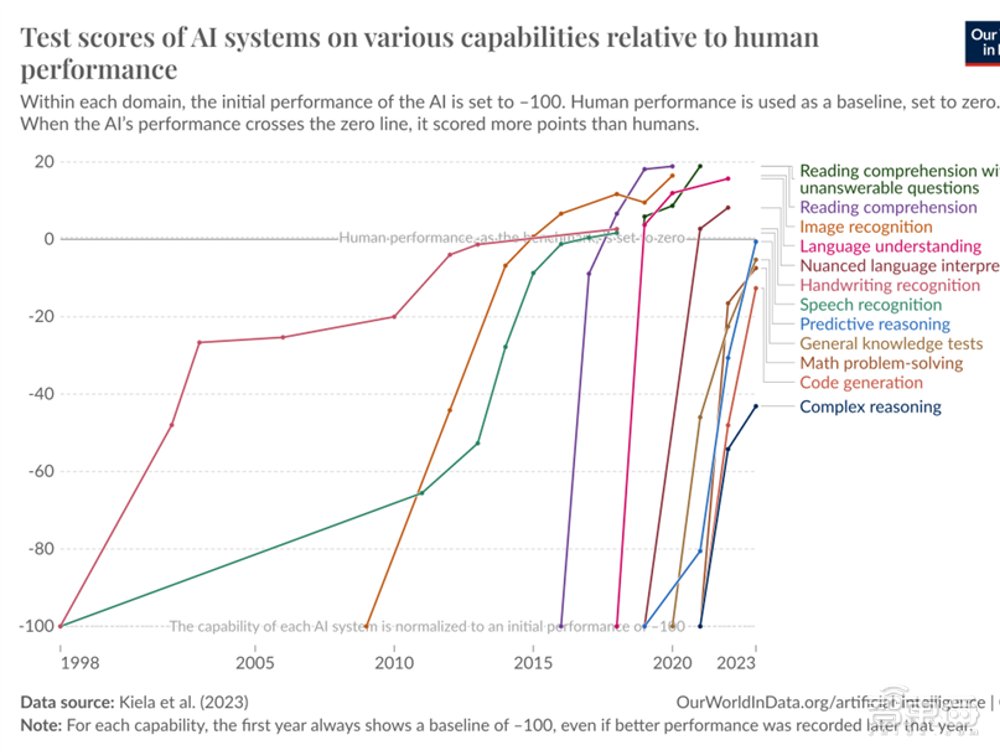
上图显示,AI正在以极快地速度在诸多基准测试中取得超越人类水平的表现。阿申布伦纳称,目前广泛使用的MMLU基准测试的设计者认为这个测试能经受住时间的考验,但仅仅3年后,像GPT-4和Gemini这样的模型就已经获得了约90%的正确率,远超大部分人类的表现。
目前最困难的基准测试是类似GPQA的测试,内容是博士级别的生物、化学和物理问题。但阿申布伦纳估计,在一代或两代模型迭代后,这一基准测试也将作废。
阿申布伦纳认为AI模型的快速进步主要有3个原因:
1、算力的增长
算力的增长不仅仅是因为摩尔定律的存在。即便是在摩尔定律的全盛时期,算力增长也相对缓慢,大约是每10年增长1-1.5个数量级。
而AI研究机构Epoch AI对2019年-2023年的算力提升进行了评估,评估结果显示GPT-4训练使用的原始计算量比GPT-2多约3000倍10000倍。
目前算力的增长速度是摩尔定律的接近5倍,这主要是因为在计算基础设施上的巨额投资。阿申布伦纳估计,到2027年底,将会出现2个数量级的算力增长。这意味着计算集群将从目前的10亿美元量级增长到数千亿美元量级。这种规模的算力集群的用电量相当于美国一个中小型的州的用电量。
2、算法效率的提升
阿申布伦纳将算法的进展分为两类,算法效率的提升属于“范式内”的算法改进,能让我们用更少的计算量实现相同的性能,这也将相应地提升整体的有效计算量。
这种范式内的算法改进速度是几乎不变的。ImageNet的最佳数据显示,2012年-2021年的9年期间,计算效率持续以每年0.5个数量级的速度提升。这意味着4年后,我们可以用现在1%的计算量实现相同的性能。
不过目前大多数AI实验室已经不在发布这方面的数据,因此很难衡量过去4年中前沿LLM(大语言模型)的算法进展。但Epoch AI最新的论文估计,LLM的算法效率提升仍然与ImageNet类似,都是每年大约0.5个数量级。预计到2027年底,与GPT-4相比,模型算法效率将提高1-3个数量级。
3、释放模型潜力的改进
这类的算法改进是极难量化的,但过去几年,AI行业的确实现了不少释放模型潜力的改进。人类反馈强化学习(RLHF)极大地提升了模型的可用性。根据OpenAI发布的关于InstructGPT的开创性论文,使用了RLHF的小模型在接受人类评分者的评估时,表现相当于比它大100倍但没有使用RLHF的大模型。

同样的,思维链(Chain of Thought)技术在两年前开始广泛使用,这让模型在数学和推理类问题上实现了10倍的有效计算提升。此外,工具使用、超长上下文窗口和后训练等技术都让模型有了极大的改进。
而目前的模型还没有长期记忆,无法进行长时段的思考并输出更长的内容,个性化程度也不够高。阿申布伦纳认为,如果我们能在这些领域取得突破,那么就有可能实现模型表现质的飞跃。
但阿申布伦纳强调,这些估计的误差是很大的。训练数据可能面临瓶颈,而算法突破何时能实现也是未知数。但目前我们确实在经历着成数量级的快速增长。只要AI技术能保持目前的发展趋势,我们就很有可能于2027年实现AGI。
阿申布伦纳认为,AI的进步不会止步于顶尖人类水平。例如,在最初学习了人类最好的棋局之后,AlphaGo开始与自己对弈,它很快实现了超越人类的水平,下出了人类永远无法想出的极具创意和复杂性的棋步。
在实现AGI后,人类将能够利用先进的AGI系统实现自动化的AI研究,这可能会将人类10年的算法进展压缩到不到1年的时间里。与现有的领先的AI实验室的数百名研究人员和工程师相比,未来的AI实验室可能会拥有成千上万个AGI系统,夜以继日地努力实现算法突破,不断自我完善,加速算法进步的现有趋势。
但这一增长也有几个可能的瓶颈。
1、算力限制:AI研究不仅需要好的想法、思维或数学计算,还需要进行实验来验证想法。虽然AI研究被自动化了,并得到了极大的加速,但这并不意味着算力也将以同样的速度增长。
2、长尾效应:人类或许能将70%的AI研究工作快速地自动化,但剩余30%的研究很有可能就变为瓶颈。
3、算法进步的内在限制:算法进步有可能无法再想过去那样提高5个数量级。
4、创新难度提升:目前AI实验室只需要几百名顶尖研究人员,便可以维持每年5个数量级的表现提升。但随着模型性能的提升,要实现同样幅度的提升的难度也相应地增加了。我们可能需要大量的研究才能维持与过去类似的算法进步速度。
尽管存在种种可能的限制,阿申布伦纳还是认为我们有可能会在2030年左右实现强大的超级AI系统。2030年左右,GPU的数量可能会达到数十亿个,而上面运行的AGI系统数量甚至有可能超过人类的数量。在几周内,它们就能获取相当于人类几十亿年才能积累的经验,还能一直高度专注地工作。
AI能力的爆发式提升将带来一系列影响。这有可能推动机器人技术的快速发展,将工厂中的工人全部替换为机器人,还有可能推动经济的高速发展和其它科学研究的快速进步。
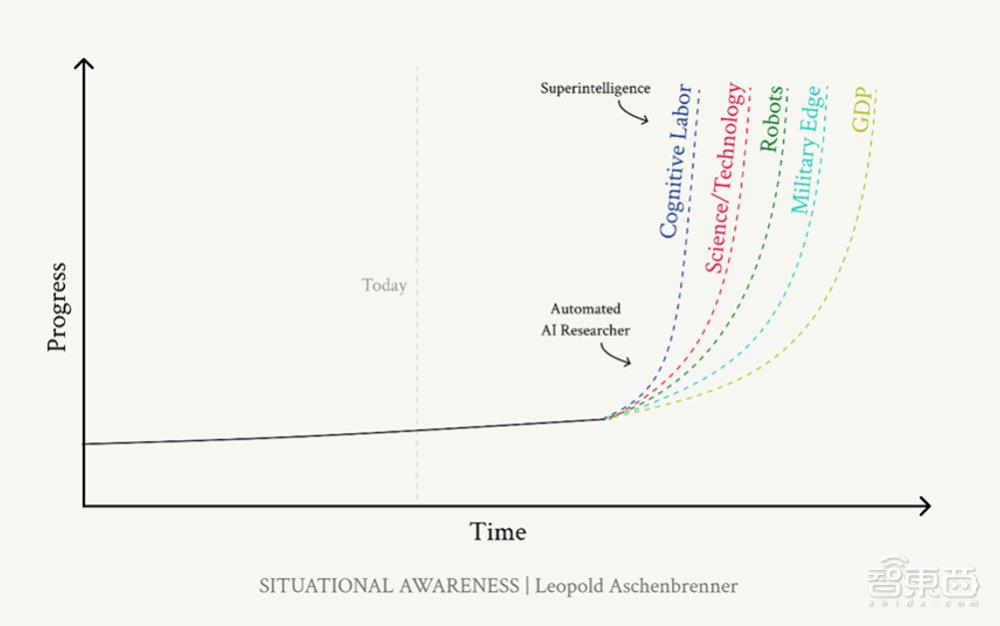
阿申布伦纳认为,智能爆炸和后超级智能时期将是人类历史上最不稳定、最紧张、最危险和最疯狂的时期之一。他认为在这一AI技术快速发展的时期中,我们几乎没有时间做出正确的决定。挑战将是巨大的,我们需要竭尽全力才能完成这一过渡。
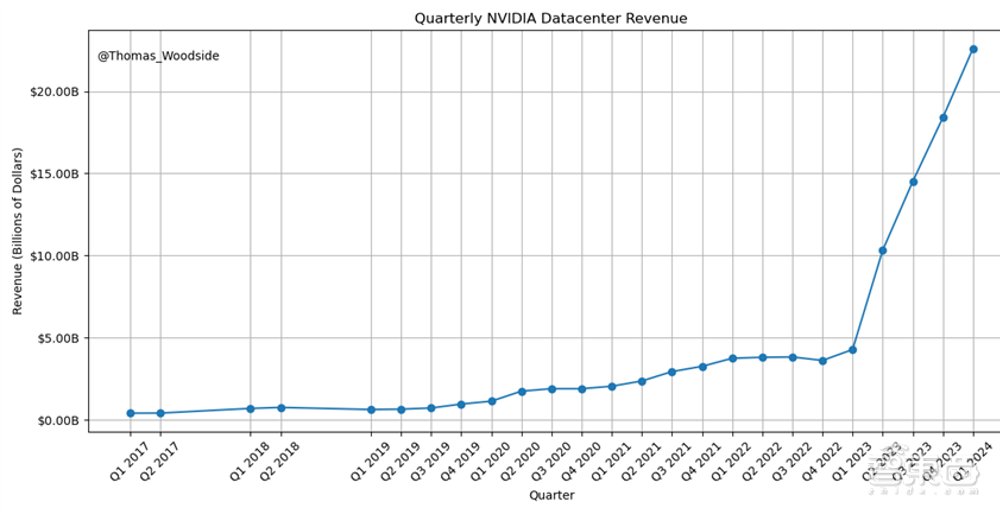
实现AGI是一场昂贵的游戏。2024年,英伟达的数据中心业务实现就实现了每季度250亿美元,也就是每年1000亿美元的营收。这就意味着流经英伟达的数据中心投资就有1000亿美元。这还不包括数据中心场地、建筑、冷却、电力的投入。
大型科技公司也一直在大幅增加资本支出:微软和谷歌的资本支出可能会超过500亿美元,亚马逊云科技(AWS)和meta今年的资本支出可能会超过400亿美元。虽然这些支出并非全部用于AI,但由于AI的蓬勃发展,它们的资本支出总额将同比增长500-1000亿美元。这些公司还在削减其他资本支出,将更多支出转移到AI上。此外,其他云提供商、公司和国家也在投资AI。
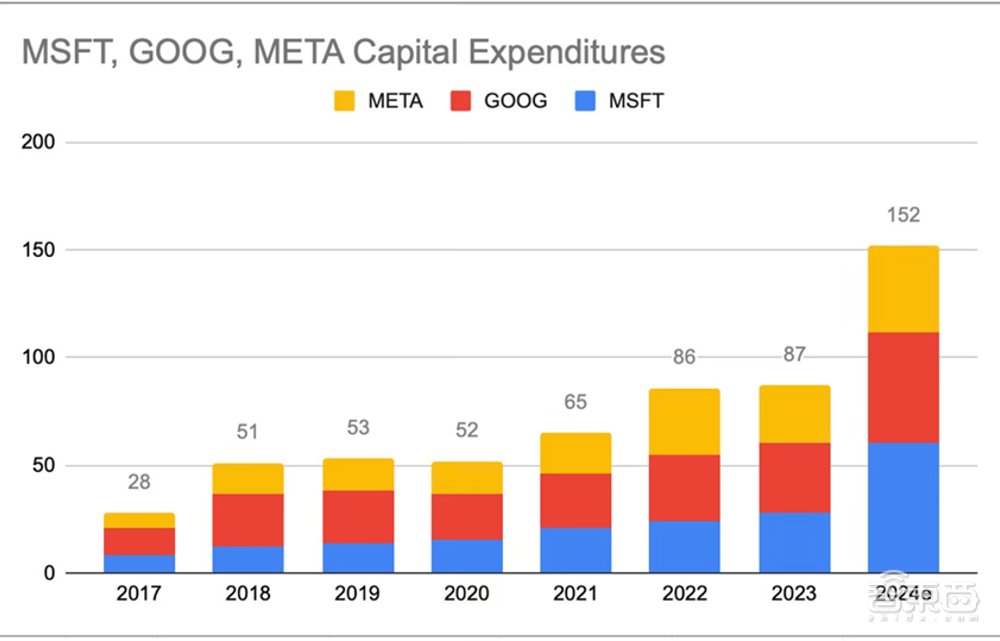
根据阿申布伦纳的粗略估计,2024年AI投资将达到1000亿至2000亿美元。到2026年,年投资额将达到5000亿美元,而到2030年,这一数字可能来到近8万亿美元。
但AI的增长可能会面临电力供应的限制。预计在2028年左右,电力就将成为一个重要的限制性因素。届时,闲置的电力产能或将不复存在,而建造一座新的千兆瓦级核电站需要10年时间。
过去10年,美国发电总量仅增长了5%。虽然公用事业公司已经意识到AI的发展对电力需求的影响,但他们对其规模并没有准确的把握。实际上,6年后,一座耗资万亿美元、用电量达100GW的计算集群就需要美国目前发电量的约20%;再加上巨大的推理能力,需求将增加数倍。
此外,芯片也是AI产业中重要的一环,但这一方面的限制可能并没有电力那么大。全球AI芯片的产量目前仅仅占台积电先进产能的不到10%,这意味着AI芯片的产量还有很大提升空间。其实台积电一年的产能如果全部用于AI芯片的生产,就可以满足万亿美元规模的计算集群的需求了。只要先进封装和高带宽内存的产能可以跟上日益增长的AI芯片需求,那AI芯片的供应就不会对AI行业的发展造成太大阻碍。
目前用于引导AI系统,确保AI系统行为与人类价值观一致的技术是“人类反馈强化学习”(RLHF),这也是ChatGPT成功背后的关键。人类评估能给AI系统反馈,对良好的行为进行强化,而对不良的行为进行惩罚,这样AI就会学会遵循人类的偏好。
但随着AI系统变得更加智能,RLHF将会崩溃,我们将面临全新的、性质不同的技术挑战。想象一下,一个超人类水平的AI系统用它发明的一种新编程语言生成一百万行代码。人工评估员根本无从知晓这些代码背后是否存在问题,他们无法做出好或坏、安全或不安全的评价,因此也无法通过RLHF强化良好行为并惩罚不良行为。

AI智能水平的爆发式提升可能会让AI系统极快地从RLHF正常工作的系统,转变到RLHF完全崩溃的系统。这使得我们几乎没有时间迭代并发现和解决问题,相关研究极有可能脱离正轨。但阿申布伦纳还是持谨慎乐观态度,认为我们可以解决对齐问题,还提出了几个可能的研究方向:
1、评估比生成更容易:写1篇论文的时间要远远长于评估1篇论文质量的时间。同理,如果我们将让专家团队花费大量时间评估每个RLHF示例,即使AI系统比他们更聪明,他们也将能够发现许多不当行为,并给予反馈。
2、可扩展的监督:我们可以使用AI助手来帮助人类监督其他AI系统。
3、泛化:评估问题时,有些问题确实超出了人类的理解范围,但我们可以研究AI系统在简单问题上的表现,然后推广到更为复杂的问题上。
4、可解释性:如果我们能理解AI系统具体在想什么,就能对AI系统实现有效的监督和对齐。
阿申布伦纳也提到,对齐仅仅是对智能爆发式增长的第一道防线,我们还需要其他形式的保护。例如提升模型的安全性,防止模型的自我渗透,还可以开发专用的监控模型,对其他AI模型进行监管,或是有意识地限制模型的能力。
阿申布伦纳在这份文件中分享了当前AI行业的一个怪现象:现在每个人都在谈论AI,但很少有人知道即将发生什么。英伟达的分析师仍然认为2024年可能就是顶峰。而主流专家则陷入了选择性忽视的状态,认为模型能力仅仅只是“下一词预测”。他们只看到炒作和一切如常,最多只是认为另一场与互联网出现规模相仿的技术变革正在发生。
这份名为《态势感知》的文件在发布后迅速在网络上引起热议,有不少网友赞同阿申布伦纳的观点,但也有人认为他在文中对智能的定义和衡量标准混乱,对趋势的判断也缺乏充分依据。
或许只有时间能告诉我们答案,但阿申布伦纳在文中提出的种种问题并非凭空捏造,人类确实需要回应超级智能可能带来的艰巨挑战。
来源:S I T U AT I O N A L AWA R E N E S S
本文地址:http://lanlanwork.gawce.com/quote/5485.html 阁恬下 http://lanlanwork.gawce.com/ , 查看更多